Excuses, excuses…
When we knowingly contravene beliefs that we perceive to be important, we tend to experience a feeling of discomfort. One theory says that we then bring in “neutralisations” – excuses that we make for ourselves, to waft away that discomfort. The idea’s been around for some time, and it’s been applied to e.g. shoplifting, and buying non-fair trade products. Typical excuses would be denial of injury (“nobody got hurt”), metaphor of the ledger (“normally I’m very good, this is an exception”), and denial of responsibility (“it wasn’t my choice”).
The principle has also been applied to cybersecurity decisions, in two important ways.
The first is shown in the work of Siponen et al., in which people were provided with neutralisations (“maybe you had to break the security rules to get your work done?”). That study found that when people were offered a way out, they were more likely to be non-compliant with security guidance. The second is shown in the work by Barlow et al., who applied measures aimed at suppressing the use of neutralisations, and found that people acted in ways that were more compliant with security rules. That second point in particular, seems to offer an easy way of improving security decision-making. Just ask people not to make excuses for themselves.
Both studies however, used self-report – instead of putting people in real-life situations and observing their behaviour, they were asked to imagine themselves in that position and to describe what they would have done.
So… in real life, would counter-neutralisations work? I ran an experiment to find out.
Process Details
Using a mock-up that was as realistic as possible, volunteers were asked to carry out an email sorting task. Some emails needed their sensitivity marking checked. Some were ok to send, some weren’t (based on security guidance provided at the start of the experiment). Some were (maybe) phishing emails.
Prior to and during the experiment, one group of people saw specially-created posters designed to deter the use of neutralisations (see example below). A second group saw standard security posters, a third group saw no posters at all.

Credit: Leapfrog Creative Ltd.
The expectation was that for the bespoke poster group, processing times would be longer in comparison with the no-poster group, but error rates would be lower, because people would be taking more time over each decision. The standard poster group was there as a cross-check (because maybe it was just seeing a poster that was having an effect).
To prompt the use of neutralisations, a note of incentivisation was introduced. Coffee shop tokens were on offer – everyone got £5 to say “thank you”, those that correctly classified seven out of the eight potential phishing emails got £7, but correctly classifying all of them got you a £10 token. Everyone taking part was told that there were only eight phishing emails. However, all eight had been placed in the first half of the set of emails. If the incentive was effective, people would be more inclined to skimp on security in the second half, when all the phishing emails had been used up.
In case you were wondering, I should probably say that this was carried out as part of an MSc, rather than me just randomly experimenting on people…
Headline Figures
When all the numbers were in, and the analysis was completed, it emerged that there was indeed a statistically significant difference in processing times between the control group and the bespoke poster group. Hurrah! So all we need to do is put up some differently-worded posters. Job done.
Well, maybe. On closer inspection, it turned out that the difference was negative. That is, on average, the bespoke poster group took significantly less time to process each email, than did the no-poster group.
Great. Well, ok. No problem. The Wright Brothers didn’t give up on their first attempt to invent the submarine. Anyway, logically, if that group is taking less time per email, then they’ll be making a greater number of mistakes. Let’s take a look at the error rate.
Turns out there was no statistically significant difference between the error rates for the two groups. The bespoke poster group were making the same decisions, but making them quicker.
At this point the emphasis shifted somewhat, away from looking for potential improvements in security decision-making, and towards figuring out what the Deuce was going on.
Analysis
In what was an absolutely inspired move/guess (thank you), I worked out the rolling average of the processing times for the three groups as the experiment progressed. Plot as below.
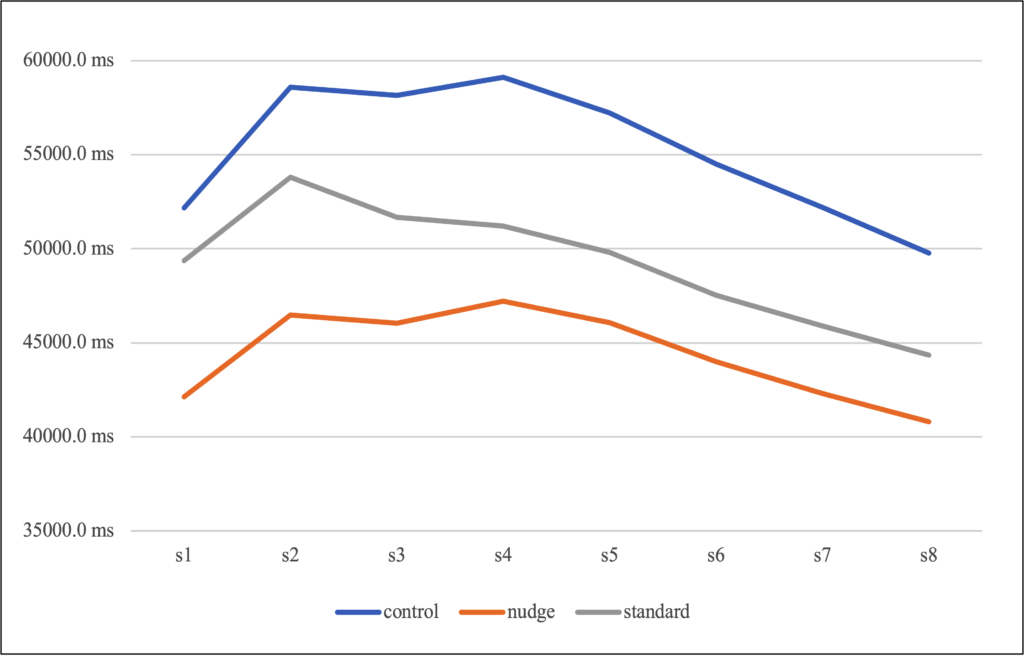
You can see immediately that there’s a more or less constant difference between the no-poster group (blue) and the bespoke poster group (orange), starting with the first question and continuing through to the last, although it does diminish a little towards the end, possibly as people became bored.
You can also see a peak in both groups at the halfway point, indicating that people were clicking on “whatever” more and more in the second half, once the possibility of being awarded tokens had run out. In fact, if you plot the average time per question across the second half, you can see that the times for both groups are declining, but also flattening out to a shared “floor”, indicating that there was a minimum time needed to process each email, no matter which group you were in. Maybe the average time required to read the email?
Finally, and in passing, you can see that the traditional security posters (grey line) made people give up and just get it over with, even before all the tokens had been found. One for the security team there.
So, we have some discretionary processing time (as shown by the peaking effect of the tokens), some fixed processing time (as shown by the levelling out) and we have some other process whose timing seems to be affected by the posters. And that probably takes place after the decision itself, because it doesn’t seem to affect the error rate.
A Suggestion
There’s a generally used model of consumer decision-making that involves five discrete stages, as below.

Need recognition is where you think “I’m hungry”. That’s usually a fairly logical process. The next stage, Search, means you go looking for potential solutions. Again, that’s usually done in a logical way, you look for food shops, not clothing shops. Then you do a comparison of the available options. At this point, things become a little less rational – you tend to make the decision based on gut feel rather than logic (“I should buy fruit, but I could really do with a burger”). So you decide to have the burger, but you feel a bit guilty about it. So we need the final stage, Rationalisation. That’s where you work out why it wouldn’t be so bad to have the burger (“it’s cheaper”, or maybe “I wouldn’t have to cook an evening meal”). And yes, those do look very much like neutralisations.
But wait a doggone minute… that looks suspiciously like the outcome of the experiment! A minimum processing time (need recognition and search), a discretionary processing time (comparison), and a variable processing time (rationalisation), the timing of that last stage being driven by circumstances.
Overall, renaming a couple of the components gets you to the adapted diagram shown below. We tend not to like making decisions, so there’s a process up front where we acknowledge ownership i.e. we accept that a decision needs to be made. The rest follows as per the consumer model.

Rather than acting on the assessment stage, the bespoke posters seemed to be affecting the process of rationalisation, making it easier for people to forgive themselves for their gut feel decision. The outcome being broadly the same decision, but with a shorter processing time.
Anyway – this adaptation is ok as far is it goes, but if it’s valid, then there ought to be some other aspects of the consumer decision model exhibited in the results. For example, anticipatory regret. Sometimes we look beyond the decision before we’ve made it, to see how our preferred option will pan out. In fact, some sources say that’s how we make the decision in the first place, by allocating emotional weightings to each option. In this case that might be “yeah, I’ll really enjoy the burger, but I’ll be bored this evening if I don’t have a meal to fill the time”. So you go for the fruit.
Some of the emails presented in the experiment had a sensitivity marking on them that was clearly wrong, at least according to the guidance supplied at the start. Some of those emails needed their marking reduced, some needed it increased. If you compare the error rate on undermarked emails with the error rate for the overmarked emails, you can get some idea of how willing people were to mark up vs their willingness to mark down. Turns out that the difference was statistically significant, with the error rate for overmarked emails being about three times that for undermarked emails. That is, if I downgrade the marking and get it wrong, I’ll be in trouble. But if I leave it as it is, even though it looks incorrect, I’m safe. In short, anticipatory regret.
What struck me immediately (and obviously) was that I’d spent a fortune only to arrive at the idea that security decisions are made in the same way as any other decision. I can’t help feeling that I could have got to that point rather more cheaply.
On the plus side, despite all the expenditure, I have a result that can be productised. Because if you want a group of people to make the same security decisions as they currently do, but you need them to make those decisions faster, then baby, I’m your man. Form an orderly queue.
Implications
If the consumer decision model does apply, then in order to affect the decision itself (rather than the time taken to make the decision), you need to flatten out the peak of irrationality at the point of the decision. If you can do that, it should apply to all security decisions, not just phishing. And there is indeed some evidence that winding down the level of bias does result in more considered decision-making.
This might seem like a slightly circular argument, but if the consumer model holds, then there’s also no point in asking people what they would have done under a specific set of circumstances. You’re asking them to describe their likely behaviour when they’re in the earlier, more rational stages of the process. So you get a rational answer. If you want to see what actually happens, you have to take them all the way through, to make an actual decision. Which, if true, could explain the difference between the findings for hands-on and those for self-report.
This next bit might seem a bit cynical, but here goes. By offering what were quite modest rewards, people were strongly motivated to find and flag up what looked like phishing emails. Under normal circumstances I guess, there’s no motivation to look closely and report things that look suspicious. But if I get two days worth of Latte out of it… 🤔
Remember, this wasn’t two weeks all expenses paid on the Maldives. It was just enough to make the feeling of reward meaningful. Come on, doing that as a corporate plan wouldn’t be any worse than a bug bounty. No, seriously…
Caveats
So, case proven? Maybe. But there are a couple of important caveats.
First, the analysis I’ve just gone through wasn’t the analysis that the experiment was designed to feed into. It was a post-hoc attempt to discover why the expected results didn’t materialise.
Second, the experiment was a little bit “underpowered”. Ideally I’d have had more people, or perhaps I should have used just two groups. On the people thing, I was (very) fortunate to have someone recruiting volunteers, and without their support I wouldn’t have had any results at all (thank you Kathleen).
Third, this was one experiment involving one set of people at one moment in time. What comes out of it is an indication, it’s not proof. But it is nonetheless an interesting outcome, albeit not exactly Earth-shattering. Basically, security decisions aren’t a special case.
Meaning that all the currently available experience in the field of consumer psychology should be applicable.
Meaning? Well, one outcome would be move over security team. And hello marketing team.
First published 20th May 2024
Edited 1st July 2024